为什么选择 KaiwuDB?
高性能时序数据处理
依托 “就地计算” 技术,KaiwuDB 实现了千万级设备接入、百万级记录秒级写入、亿级数据秒级读取的读写性能,在国际数据库性能基准测试 BenchANT(Time Series)中,写入吞吐领先同类产品 1.5-1.8 倍,位居全球第一
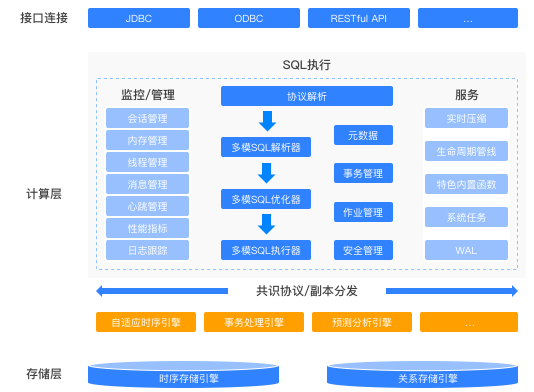
多模融合架构
采用原生多模内核,集成自适应时序引擎、事务处理引擎、预测分析引擎等多模引擎,通过统一接入层实现时序数据、关系型数据的统一采、存、算、管,实现多模数据存储对上层应用的透明化
分布式架构
采用节点全对等无中心架构,避免单点故障;支持节点在线水平扩展,性能随节点数量线性提升,可轻松支撑 PB 级数据存储与管理;通过多副本与Raft协议,实现故障自愈;同时支持单副本与多副本灵活配置,适配不同业务的可用性要求
低成本存储
通过三大核心技术实现存储成本优化:1. 数据压缩比5-30 倍,时序数据经特有算法压缩后可节省 90% 存储空间;2. 支持生命周期管理,过期数据自动清理,降低存储成本;3. “时间热度” 分级存储,自动将冷数据迁移至低成本存储介质,热数据保留在高性能存储中,平衡性能与成本
原生AI
AI 分析能力原生集成于数据库内核,提供可插拔式 AI 分析预测功能,支持模型的导入、训练、预测、评估与替换全流程;兼容主流机器学习框架,内置OpenTS时序基础大模型;无需将数据导出至第三方 AI 平台,即可在数据库内完成实时分析与预测,彰显了 “数据即分析、分析即决策” 的核心价值
安全稳定合规
通过公安部等保三级认证、国家保密测评,构建从身份认证、权限管理、访问控制、数据存储传输加密、安全审计等全方位的安全体系,满足能源、电力、制造、车联网等关键行业的合规要求
主要/亮点功能
多模融合架构
通过统一内核设计,实现时序、关系、非结构化数据的原生融合处理,打破传统单模数据库的“孤岛效应”和“业务架构复杂”的痛点问题;
- 统一SQL接口实现多模数据的跨模查询
- 集成时序引擎、事务引擎、分析引擎,支持时序数据、关系型数据等多类数据统一存储
- 避免多库部署复杂度,异构数据零ETL实时聚合
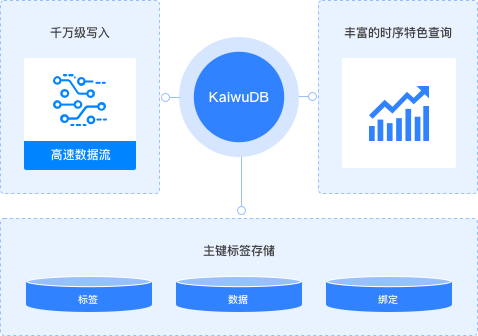
极速写入查询
创新引入“主键标签”机制,基于主键标签的智能路由,降低时序数据写入延迟;借助“就地计算”、“主键标签索引”、“数据重组”等快速定位数据位置,实现亿级时序数据秒级响应
- 高性能数据写入:KaiwuDB 支持标准SQL写入、批量写入、无模式写入等多种写入方式;借助“就地计算”等技术提升数据吞吐量;
- 高速数据查询分析:KaiwuDB提供最新值、插值、降采样等丰富的时序特色查询能力;支持窗口切分、多表关联、分组聚合查询、跨模查询,满足时序分析场景;
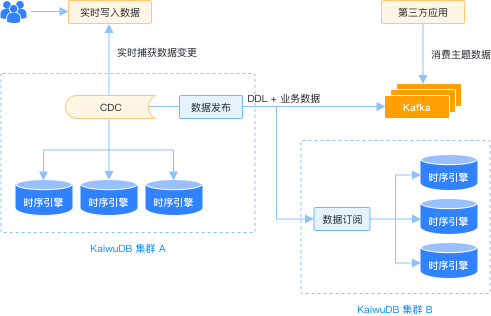
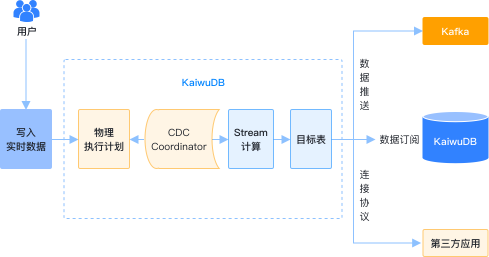
数据分发
数据分发功能包含数据推送和数据订阅发布,允许将一个库、一张表、甚至SQL查询结果发布至 Kafka 或另外一个 KaiwuDB 实例,实现数据的共享与同步;
- 提供整库、全表数据的初始化能力
- 支持基于SQL条件的行过滤和列级投影
- 实时捕获数据的增量变
- 在故障恢复时从断点继续同步,避免数据重复或遗漏
流计算
内置开箱即用的流计算功能,用户可通过标准 SQL 定义任务,当数据写入源表后,按着定义方式(包含计算规则、过滤条件等)自动处理,并将处理结果写入目标表;可替代传统复杂流处理系统,降低系统复杂度和运维成本;流计算可用于智能降采样、预计算加速,显著提升查询响应速度。
- 支持断点续传
- 支持过期数据、历史数据、乱序数据等多种处理策略
- 目标表支持关系和时序
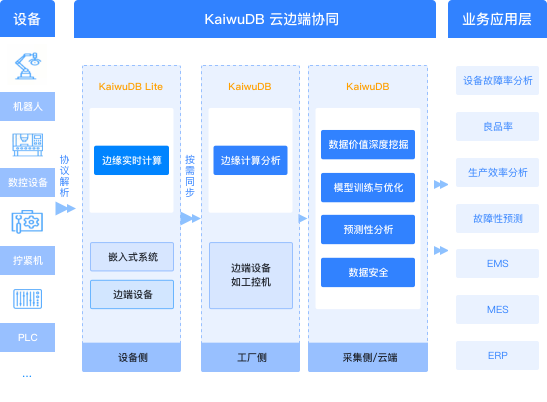
云边端协同
和KaiwuDB Lite共同构建完善的云边协同体系,KaiwuDB Lite部署在资源有限的设备测或嵌入式系统,基于轻量化架构和高压缩能力,实现传感器和设备数据的实时采集、处理、存储和查询;边侧或云侧,部署KaiwuDB,借助KaiwuDB的各种能力,将来在端侧的数据统一汇聚分析,支撑实时决策、运行监测预警、业务洞察等;
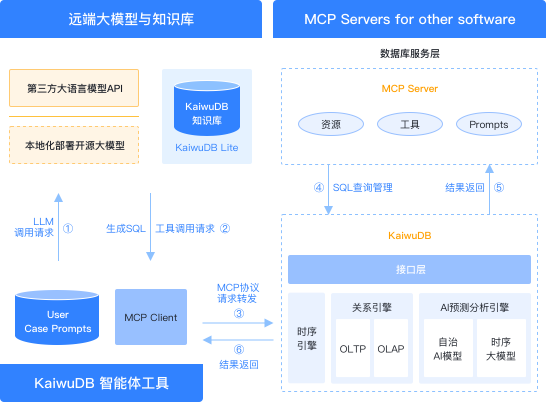
AI 数据库智能体
基于 Model Context Protocol(MCP)协议构建,深度融合自然语言处理与数据库技术,用户通过简单的对话即可完成产品使用智能问答、自动化安装部署、自然语言查询分析、故障诊断和性能调优。通过借助大语言模型(LLM)智能提示能力、结合知识库和向量搜索技术,降低 KaiwuDB 的学习、使用和运维成本,提升数据交互效率。
- 智能巡检:定期对数据库运行状态、存储容量、慢SQL等巡检,将“事后干预”变为“事前预警”
- 性能优化:定位性能瓶颈,提供性能分析报告,生成优化方案
- 数据管理与分析:自然语言式数据查询,业务数据趋势预测分析
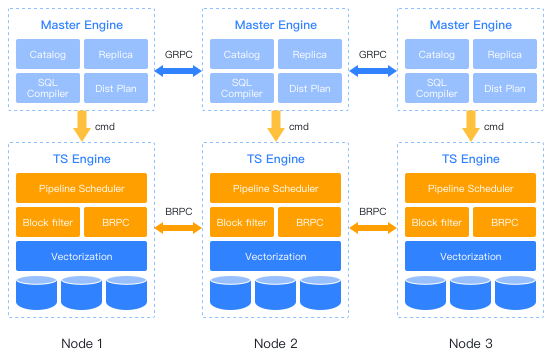
核心技术优势
时序执行引擎