行业痛点
实时数据采集难保障
能源电力行业时序数据来源涵盖风光储设备、电网设施、用户电表等多场景,采集频率达秒级/分钟级,且存在设备协议异构、偏远区域信号不稳定、极端工况数据丢失等问题,导致全链路数据实时同步与一致性难以保障,影响调度、运维决策准确性。
数据存储计算回溯三负荷
电力生产消费全环节每日产生海量高并发时序数据,传统架构难以支撑高并发写入、长期低成本存储需求;同时调度优化、负荷预测需毫秒级实时计算,故障溯源、合规审计需高效历史回溯,三重需求叠加形成显著技术负荷。
业务数据价值难转化
海量设备运行、能耗监测等时序数据与EMS等业务系统割裂,缺乏适配电力场景(故障预测、调峰调度、新能源出力预测)的算法模型,数据 “存而不用”,难以通过趋势分析、异常识别转化为生产运维的精准决策支撑。
数据合规安全要求高
数据层面存在标准不统一、元数据缺失、异常值较多等治理难题,影响数据可用性;同时,数据涉及电网核心运行信息与用户隐私,需满足本地化存储、传输加密、权限管控等合规要求,如何平衡数据安全与业务高效运转成为关键痛点。
能源电力一体化解决方案
针对能源电力行业时序数据采集实时一致性差、存储计算回溯负荷高、业务融合价值转化不足、治理合规安全难平衡四大核心挑战,打造以 KaiwuDB 为核心时序数据底座,联动浪潮开务行业数智大脑(K-mind)、数据服务平台(KDP) 的一体化解决方案: KaiwuDB 依托原生时序数据库技术特性,解决多源数据实时采集、海量时序数据存储/计算/回溯的核心问题;通过与 K-mind 打通数据链路,实现电力场景算法建模与价值转化;联动 KDP 完成全链路数据治理,同时内置细粒度安全管控能力,全面适配能源电力行业时序数据全生命周期管理需求。
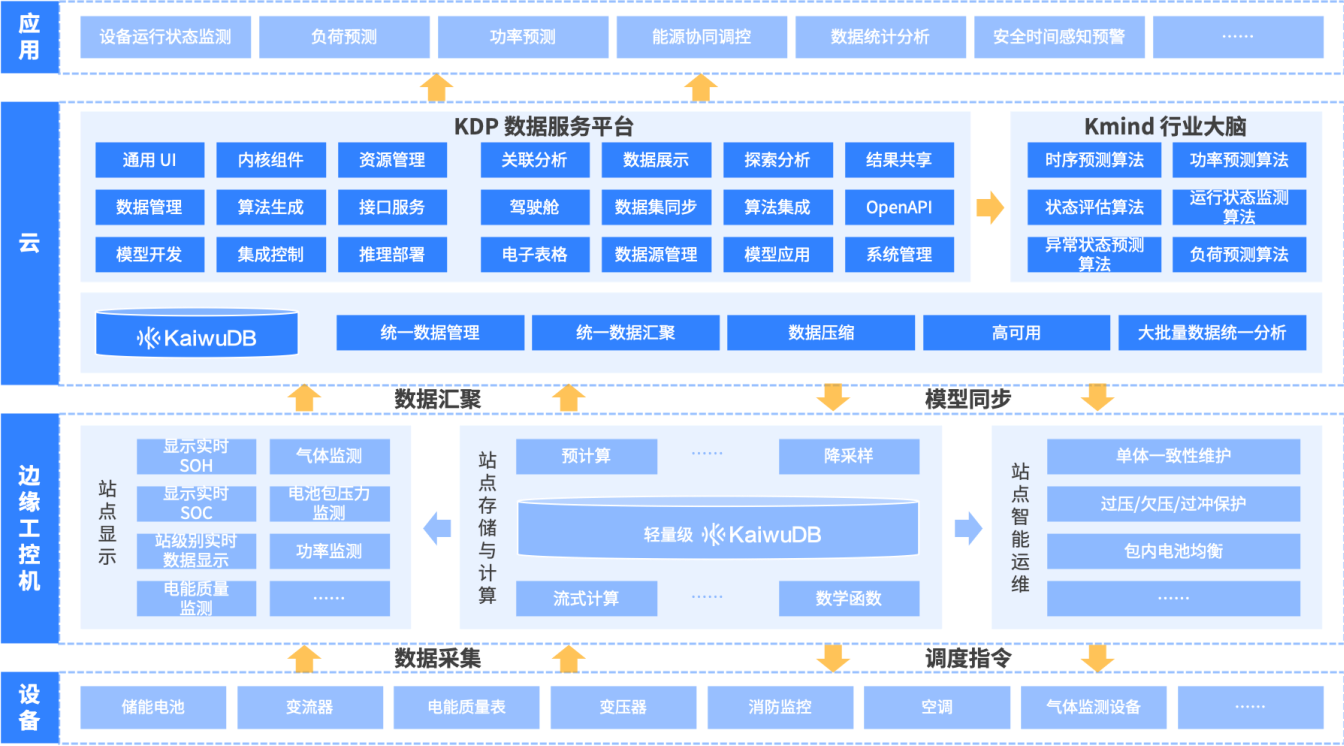
方案价值
数据一致性显著提升
依托KaiwuDB对 Modbus、OPC UA 等电力行业主流协议的适配能力,搭配实时数据校验、断点续传及一致性同步机制,破解多源异构设备数据采集不同步、偏远区域信号不稳定、极端工况数据丢失等痛点,为后续数据处理与业务应用提供可靠数据源。
系统性能大幅提升
通过KaiwuDB分布式架构支撑百万级QPS高并发写入,冷热分层存储降低长期归档成本,毫秒级聚合计算引擎与专属时序索引提升处理效率,有效应对海量时序数据存储压力大、实时计算响应慢、历史回溯效率低的挑战,满足电力调度优化、故障溯源等核心场景需求。
打通数据价值转化链路
以 KaiwuDB 为统一时序数据底座,将标准化的设备运行、能耗监测等数据无缝对接浪潮开务行业数智大脑,通过行业专属算法模板解决数据与业务场景融合不深、“存而不用” 的痛点,转化为故障预测、调峰调度等精准决策支撑,实现数据到业务价值的闭环。
数据治理与合规达成平衡
借助KaiwuDB数据治理平台完成电力时序数据标准统一、元数据管理与质量清洗,搭配KaiwuDB细粒度权限管控、传输加密及操作审计能力,破解数据标准混乱、质量参差不齐、安全合规风险高的双重难题,既提升数据可用性,又满足电网核心数据保护与用户隐私合规要求。