行业痛点
高并发时序数据写入
单座高炉即包含数百个传感器,全厂区设备传感器总数可达上万甚至数十万个,数据写入峰值常突破每秒百万级。传统数据库因架构限制,写入性能存在上限,易出现数据丢失、延迟堆积,导致生产状态无法实时同步,影响工艺调整的及时性。
数据存储成本高、难运维
生产过程数据及设备运行数据等需长期留存用于工艺优化和合规审计,数据量每年以PB级增长。传统存储方案(如单机数据库+磁盘阵列)不仅硬件投入大,且数据压缩比低,存储成本居高不下;同时,单机架构无法横向扩展,后续扩容需停机维护,影响生产连续性。
多维度查询分析效率低
业务中常需结合“时间维度(如某时间段)+设备维度(如某台高炉)+工艺维度(如某批次冶炼参数)+质量维度(如钢材成分)”进行跨维度查询。传统数据库缺乏时序优化引擎,多表关联查询与历史数据回溯效率极低,单次查询可能耗时数分钟,无法支撑实时工艺调整与故障诊断。
多源数据融合分析弱
冶金行业数据来源分散,设备时序数据、生产业务数据、物料数据、质检数据分属不同系统,数据格式与存储方式各异。传统方案难以实现多源数据的统一接入、关联建模与协同分析,导致“数据孤岛”问题突出,无法充分挖掘数据价值,制约了设备预测性维护、能耗精准管控、质量全流程追溯等智能化应用的落地。
冶金全链路一体化解决方案
以KaiwuDB为核心,我们为用户构建“数据采集-存储计算-数据应用”的全链路一体化架构,打通冶金行业多源数据壁垒,支撑生产、运维、质量、能耗等全场景智能化需求。
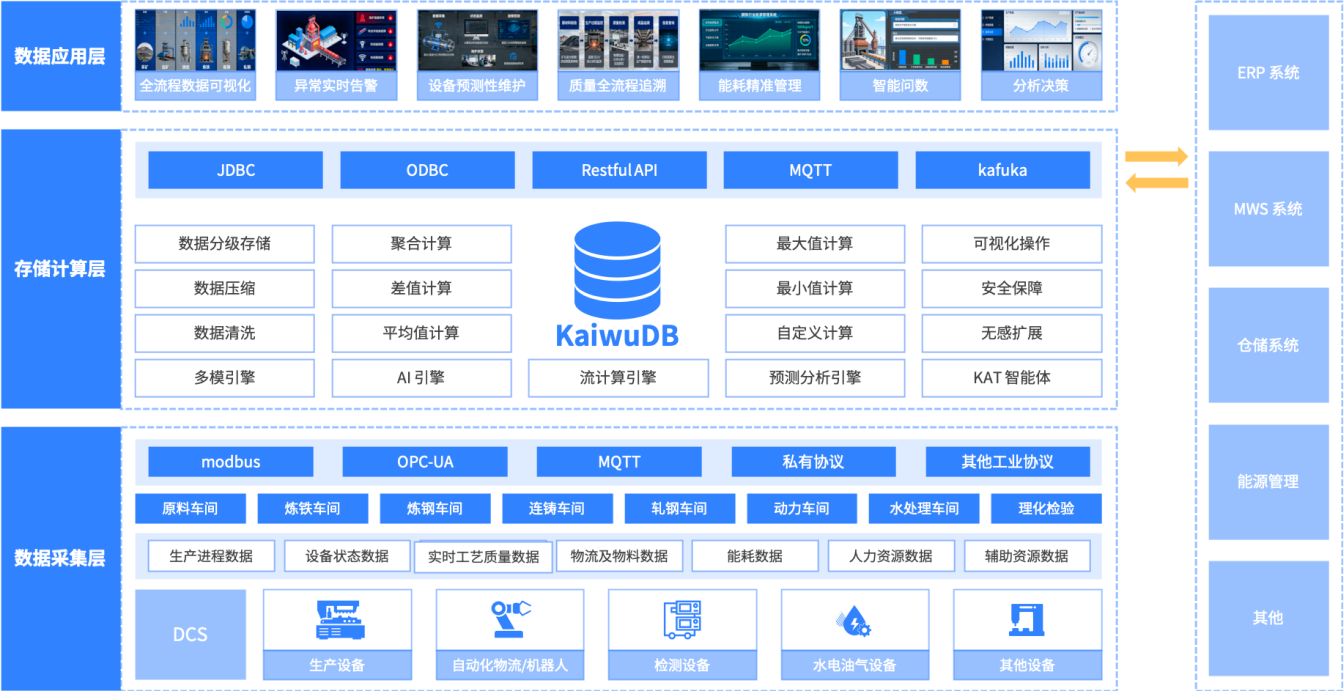
数据采集层:多源数据统一接入。通过工业网关、边缘计算节点、API接口等方式,实现全场景数据的实时采集与预处理。包括设备时序数据、生产业务数据、质量检测数据和能耗环境数据。数据采集层支持协议解析与数据清洗,确保数据完整性与一致性后,向存储计算层传输。
存储计算层:承担“海量数据存储+高效计算分析”双重职责。采用分布式架构设计,通过分片存储与并行写入引擎实现时序数据高并发写入处理,支持每秒百万级时序数据写入,适配冶金行业设备密集型场景的峰值写入需求,确保数据零丢失、无延迟;基于时序数据特性优化的列式存储与高压缩算法(压缩比可达30:1)实现海量数据低成本存储,大幅降低PB级历史数据的存储成本;通过多维度融合计算实现时序数据与结构化业务数据的关联建模;通过高可靠分布式部署实现节点故障自动切换,无单点故障风险,保障生产场景下的数据连续性与服务可用性;通过统一能力输出实现通过标准化接口向上层应用提供数据服务,将预处理后的分析结果推送至应用层,降低业务系统开发复杂度。
数据应用层:全场景智能化落地,基于KaiwuDB提供的数据支撑,对接冶金行业核心业务场景实现生产实时监控、设备预测性维护、质量全流程追溯、能耗精准管控、工艺参数优化。基于历史数据挖掘最优工艺组合,提升生产效率与产品合格率。
方案价值
效率提升:支撑实时决策与智能优化
KaiwuDB的高并发写入能力确保生产数据实时采集无积压,低延迟查询(毫秒级响应实时数据、秒级回溯历史数据)支撑工艺调整、故障预警等场景的实时决策;多维度融合分析能力让数据价值充分释放,助力工艺参数优化、设备故障提前预警。
成本优化:降低存储与运维开销
KaiwuDB的高压缩比特性使海量时序数据存储成本降低30%-50%,冷热数据分层存储进一步优化成本结构;分布式架构支持横向扩展与自动化运维,无需停机扩容,减少运维人力投入,降低系统升级风险。
场景赋能:打通全链路数字化闭环
方案以KaiwuDB为核心,实现设备、生产、质量、能耗等多源数据的统一管理与融合分析,赋能生产监控、设备运维、质量追溯、能耗管控等全场景智能化应用,推动冶金行业从“经验驱动”向“数据驱动”转型。
稳定可靠:保障生产连续性
KaiwuDB具备高可用性与数据可靠性,主从复制、故障自动切换机制确保系统无单点故障,数据持久化存储与备份策略防止数据丢失,完全适配冶金行业7×24小时连续生产的严苛要求,为数字化转型提供稳定支撑。