关系表
创建表
CREATE TABLE 语句用于在数据库中创建新表。
所需权限
- 非三权分立模式下,用户是
admin角色的成员或者拥有数据库的 CREATE 权限。默认情况下,root用户属于admin角色。 - 三权分立模式下,用户是
sysadmin角色的成员或者是拥有所属数据库 CREATE 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。
语法格式
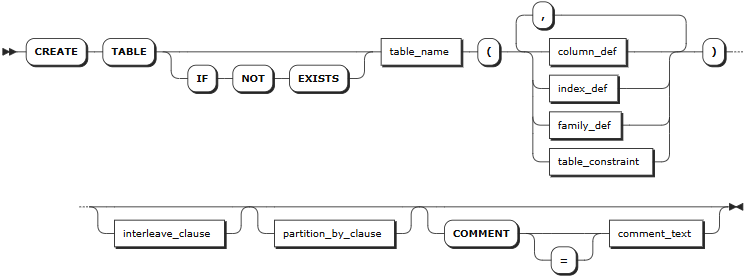
column_def
col_qualification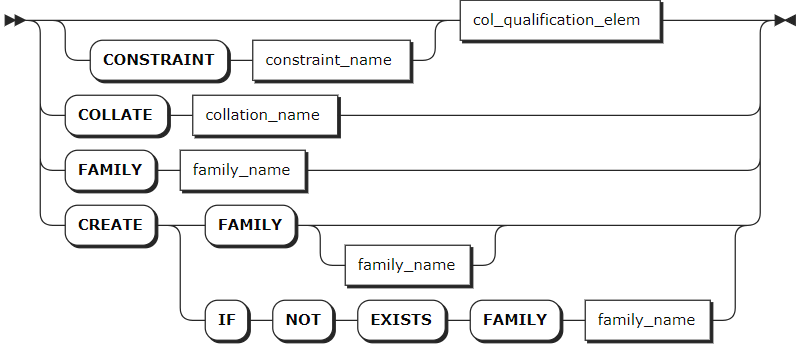
col_quailfication_elem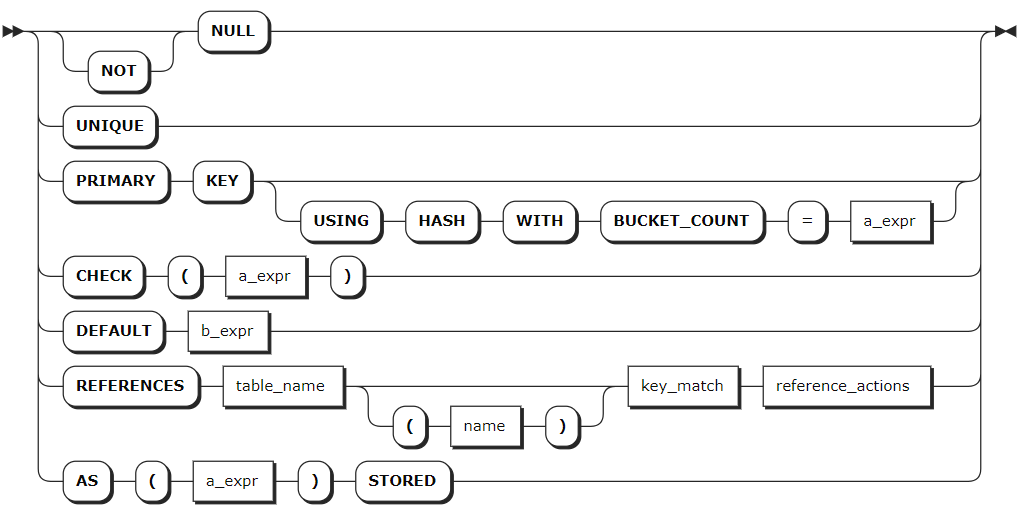
index_def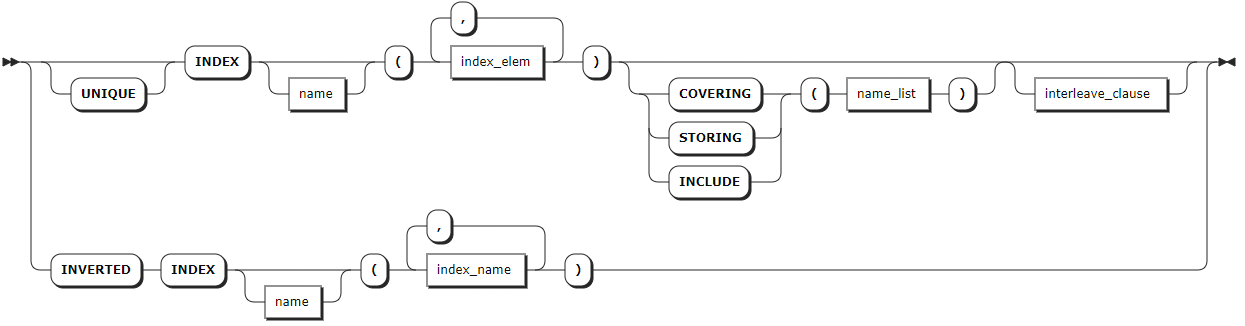
family_def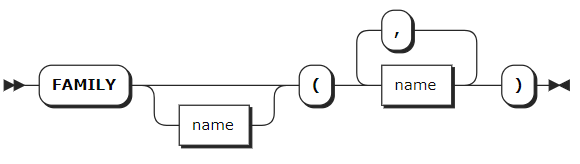
table_constraint
constraint_elem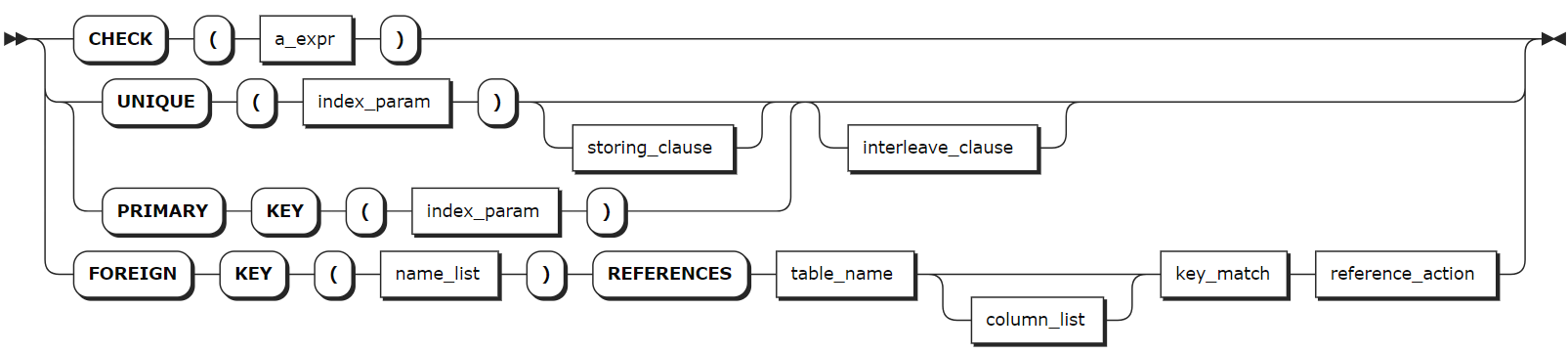
interleave_clause
partition_by_clause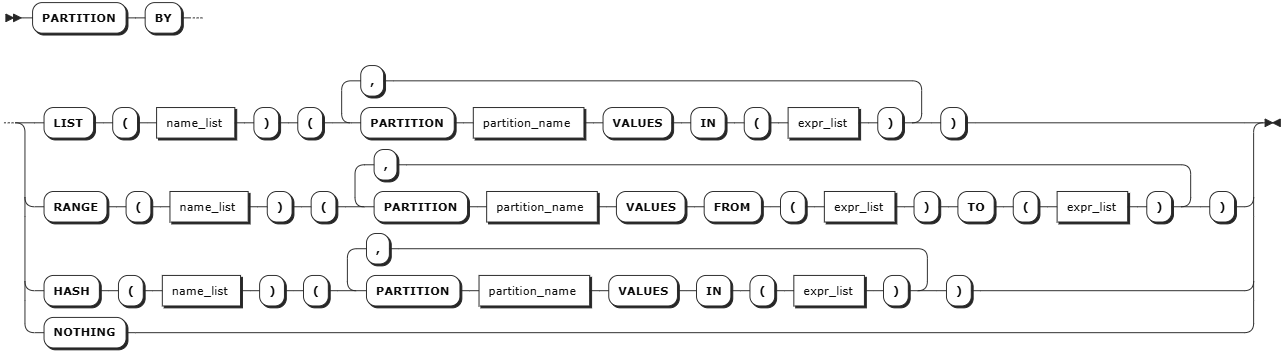
参数说明
说明
配置可选参数时,必须严格按照 [<column_def> | <index_def> | <family_def> | <table_constraint>] [<interleave_clause>] [<partition_by_clause>] [COMMENT [=] <'comment_text'>] 的顺序,否则系统将会报错。
| 参数 | 说明 |
|---|---|
IF NOT EXISTS | 可选关键字。当使用 IF NOT EXISTS 关键字时,如果目标数表不存在,系统创建目标表。如果目标表存在,系统创建表失败,但不会报错。当未使用 IF NOT EXISTS 关键字时,如果目标表不存在,系统创建目标表。如果目标表存在,系统报错,提示目标表已存在。说明 IF NOT EXISTS 仅检查表名,不检查现有表是否具有新表的相同列、索引、约束等。 |
table_name | 待创建的表的名称。该名称在数据库中必须唯一,并且遵循数据库标识符规则。支持通过 <database_name>.<table_name> 指定其他数据库中的表。如未指定,则默认使用当前数据库。 |
column_def | 列定义列表,支持定义一列或多列,各列之间使用逗号(,)隔开。列名在表中必须唯一,但可以与索引或约束同名。每列必须定义列名、数据类型,可以选择定义列级注释信息、约束或其他列限定(例如计算列),格式为格式为 <column_name> <typename> [COMMENT [=] 'commonent_text'][col_qual_list]。- 支持在数据类型之后添加数据列的注释信息。注释信息与数据列的其他约束不区分顺序。 - 在列级别定义的主键、唯一性约束、检查约束将作为表创建的一部分移动到表级别。 - 支持使用 SHOW CREATE TABLE 语句在表级别查看在列级别定义的注释信息、主键、唯一性约束、和检查约束。 - 如需实现行级强制访问控制,创建表的时候需要明确指定标记列的名称,类型为 STRING(4000)。KaiwuDB 最多支持创建一列标记列,且不允许创建标记列时指定默认值。 |
index_def | 可选项,定义索引列表,支持定义一个或多个索引,各索引之间使用逗号(,)隔开。每个索引必须指定要索引的列,可选择指定名称。 索引名称在表中必须唯一,并且遵循数据库标识符规则。有关如何创建索引的详细信息,参见创建索引。 |
family_def | 可选项,列族定义列表,支持定义一个或多个列族,各列族之间使用逗号(,)隔开,格式为 FAMILY [family_name] (name_list)。列族名称在表中必须唯一,但可以与列、约束或索引同名。列族是一组以单个键值对的形式存储在底层键值存储中的列,KaiwuDB 自动将列分组到列族中,以确保有效的存储和性能,也支持用户手动将列分配给列族。 |
table_constraint | 可选项,表级约束隔列表,支持定义一个或多个约束,各约束之间使用逗号(,)隔开,格式为 CONSTRAINT <constraint_name> <constraint_elem>。约束名称在表中必须唯一,但可以与列,列族或索引具有相同的名称。 |
interleave_clause | 可选项,支持使用交错索引(Interleaving Indexes)优化查询性能, 格式为 INTERLEAVE IN PARENT <table_name> (<name_list>)。这会改变 KaiwuDB 存储数据的方式。 |
partition_by_clause | 可选项,允许用户在行级别定义表分区,支持按列表、范围和哈希值定义表分区。更多信息,参见分区。 |
[COMMENT [=] <'comment_text'> | 可选项,定义表的注释信息。 |
语法示例
创建表,但未定义表的主键。
在关系数据库中,每个表都需要一个主键。 如果未明确定义主键,系统会自动添加名为
rowid,数据类型为 INT8 的列作为主键。KaiwuDB 支持使用unique_rowid()函数确保新行始终默认为唯一的rowid值。系统支持自动为主键创建索引。严格地说,系统没有为主键创建唯一索引; 主键由数据存储层的 key 来区分,因此不需要额外的存储空间。但在执行SHOW INDEX等命令时,系统会将其显示为正常的唯一索引。以下示例创建一个名为
logon的表,但未定义主键。-- 1. 创建 logon 表。 CREATE TABLE logon (user_id INT, logon_date DATE); CREATE TABLE -- 2. 查看表的列。 SHOW COLUMNS FROM logon; column_name | data_type | is_nullable | column_default | generation_expression | indices | is_hidden | is_tag --------------+-----------+-------------+----------------+-----------------------+-----------+-----------+--------- user_id | INT4 | true | NULL | | {} | false | false logon_date | DATE | true | NULL | | {} | false | false rowid | INT8 | false | unique_rowid() | | {primary} | true | false (3 rows) -- 3. 查看表的索引。 SHOW INDEX FROM logon; table_name | index_name | non_unique | seq_in_index | column_name | direction | storing | implicit -------------+------------+------------+--------------+-------------+-----------+---------+----------- logon | primary | false | 1 | rowid | ASC | false | false (1 row)创建表并定义表的主键。
以下示例创建一个名为
t1的表。该表拥有三列数据,其中第一列是主键列,第二列配置唯一性约束,第三列没有配置约束。系统为主键列和配置唯一性约束的列自动创建索引。-- 1. 创建 t1 表。 CREATE TABLE t1 (user_id INT PRIMARY KEY, user_email STRING UNIQUE, logoff_date DATE); CREATE TABLE -- 2. 查看表的索引。 SHOW INDEX FROM t1; column_name | data_type | is_nullable | column_default | generation_expression | indices | is_hidden | is_tag --------------+-----------+-------------+----------------+-----------------------+-----------------------------+-----------+--------- user_id | INT4 | false | NULL | | {primary,t1_user_email_key} | false | false user_email | STRING | true | NULL | | {t1_user_email_key} | false | false logoff_date | DATE | true | NULL | | {} | false | false (3 rows)创建具有二级索引和倒排索引的表。
以下示例创建一个名为
vehicles的表,并为表创建二级索引和倒排索引。二级索引允许使用除主键以外的其他键有效访问数据。反向索引允许有效访问 JSONB 列中的无模式数据。-- 1. 创建 vehicles 表。 CREATE TABLE vehicles ( id UUID NOT NULL, city STRING NOT NULL, type STRING, owner_id UUID, creation_time TIMESTAMP, status STRING, current_location STRING, ext jsonb, CONSTRAINT "primary" PRIMARY KEY (city ASC, id ASC), INDEX vehicles_auto_index_fk_city_ref_users (city ASC, owner_id ASC), INVERTED INDEX ix_vehicle_ext (ext), FAMILY "primary" (id, city, type, owner_id, creation_time, status, current_location, ext) ); CREATE TABLE -- 2. 查看表的索引。 SHOW INDEX FROM vehicles; table_name | index_name | non_unique | seq_in_index | column_name | direction | storing | implicit -------------+---------------------------------------+------------+--------------+-------------+-----------+---------+----------- vehicles | primary | false | 1 | city | ASC | false | false vehicles | primary | false | 2 | id | ASC | false | false vehicles | vehicles_auto_index_fk_city_ref_users | true | 1 | city | ASC | false | false vehicles | vehicles_auto_index_fk_city_ref_users | true | 2 | owner_id | ASC | false | false vehicles | vehicles_auto_index_fk_city_ref_users | true | 3 | id | ASC | false | true vehicles | ix_vehicle_ext | true | 1 | ext | ASC | false | false vehicles | ix_vehicle_ext | true | 2 | city | ASC | false | true vehicles | ix_vehicle_ext | true | 3 | id | ASC | false | true (8 rows)使用自动生成的唯一行 ID 创建表。
以下示例创建一个名为
users的表。系统自动生成唯一的id行,其中列的数据类型为 UUID,使用gen_random_uuid()函数的值作为该列默认值。-- 1. 创建 users 表。 CREATE TABLE users ( id UUID NOT NULL DEFAULT gen_random_UUID(), city STRING NOT NULL, name STRING NULL, address STRING NULL, credit_card STRING NULL, CONSTRAINT "primary" PRIMARY KEY (city ASC, id ASC), FAMILY "primary" (id, city, name, address, credit_card) ); CREATE TABLE -- 2. 向表中写入数据。 INSERT INTO users (name, city) VALUES ('Petee', 'new york'), ('Eric', 'seattle'), ('Dan', 'seattle'); INSERT 3 -- 3. 查看表的内容。 SELECT * FROM users; id | city | name | address | credit_card ---------------------------------------+----------+-------+---------+-------------- 163dc2f6-ebe6-4aa7-aba7-c1e54062ef5c | new york | Petee | NULL | NULL 1c9d094d-f761-4c27-9b4e-9891270af25b | seattle | Dan | NULL | NULL 7fb34aa5-2034-4ffe-97d5-679316a1acce | seattle | Eric | NULL | NULL (3 rows)以下示例创建一个名为
users2的表。系统自动生成唯一的id行,其中列的数据类型为 BYTES,使用UUID_v4()函数的值作为该列的默认值。-- 1. 创建 users2 表。 CREATE TABLE users2 ( id BYTES DEFAULT UUID_v4(), city STRING NOT NULL, name STRING NULL, address STRING NULL, credit_card STRING NULL, CONSTRAINT "primary" PRIMARY KEY (city ASC, id ASC), FAMILY "primary" (id, city, name, address, credit_card) ); CREATE TABLE -- 2. 向表中写入数据。 INSERT INTO users2 (name, city) VALUES ('Anna', 'new york'), ('Jonah', 'seattle'), ('Terry', 'chicago'); INSERT 3 -- 3. 查看表的内容。 SELECT * FROM users2; id | city | name | address | credit_card -------------------------------------+----------+-------+---------+-------------- \x574eb48921ba42c297cdf5242f2a2c21 | chicago | Terry | NULL | NULL \x5f81aee68c4943c09f8222723910ec45 | new york | Anna | NULL | NULL \x83923b3114294cfca3df26245b54e29b | seattle | Jonah | NULL | NULL (3 rows)上述两种方式生成的 ID 都是 128 位,几乎不可能产生重复值。一旦表超出单个键值范围(默认为 64 MB),新的 ID 将散布在表的所有范围内,因此可能分布在不同的节点上,由多个节点分担负载。这种方法的缺点是创建一个在直接查询中可能没有用的主键,可能需要与另一个表或辅助索引联接。
如果需要在相同的键值范围内生成的 ID,可以将列类型设置为整数类型,将
unique_rowid()函数的值作为默认值,或者通过 SERIAL 伪类型自动生成 ID,如下所示:-- 1. 创建 users3 表。 CREATE TABLE users3 ( id INT8 DEFAULT unique_rowid(), city STRING NOT NULL, name STRING NULL, address STRING NULL, credit_card STRING NULL, CONSTRAINT "primary" PRIMARY KEY (city ASC, id ASC), FAMILY "primary" (id, city, name, address, credit_card) ); CREATE TABLE -- 2. 向表中写入数据。 INSERT INTO users3 (name, city) VALUES ('Blake', 'chicago'), ('Hannah', 'seattle'), ('Bobby', 'seattle'); INSERT 3 -- 3. 查看表的内容。 SELECT * FROM users3; id | city | name | address | credit_card ---------------------+---------+--------+---------+-------------- 962382415902769153 | chicago | Blake | NULL | NULL 962382415902834689 | seattle | Hannah | NULL | NULL 962382415902867457 | seattle | Bobby | NULL | NULL (3 rows)写入数据后,
unique_rowid()函数将根据时间戳和执行写入的节点的 ID 生成默认值。除非每个节点每秒生成大量 ID(100,000+),这样生成的时间顺序值可能是全局唯一的。然而,即使使用该函数,也可能存在间隙,不能完全保证生成的 ID 是按顺序递增的。创建具有外键约束的表。
外键约束确保一个列只使用其引用的列中已经存在的值,而这些引用的列必须来自另一个表。这个约束有助于维护两个表之间的引用关系的完整性。
在外键的规则中,有两条最重要的规则:
- 外键列必须创建索引。如果在
CREATE TABLE语句中未使用INDEX、PRIMARY KEY或UNIQUE定义索引,则外键列将自动创建二级索引。 - 引用的列必须包含唯一值。这意味着
REFERENCES子句必须与主键或唯一约束的列完全相同。
KaiwuDB 支持在外键约束中包含外键操作,以指定在更新或删除引用的列时要采取的操作。默认操作是
ON UPDATE NO ACTION和ON DELETE NO ACTION。以下示例中使用了ON DELETE CASCADE,当外键约束引用的行被删除时,所有相关行也将被删除。-- 1. 创建 users 表。 CREATE TABLE users ( id UUID PRIMARY KEY DEFAULT gen_random_UUID(), city STRING, name STRING, address STRING, credit_card STRING, dl STRING UNIQUE CHECK (LENGTH(dl) < 8) ); CREATE TABLE -- 2. 创建 vehicles 表,该表引用 users 表中的 id 的值作为 owner_id 的值。 CREATE TABLE vehicles ( id UUID NOT NULL DEFAULT gen_random_UUID(), city STRING NOT NULL, type STRING, owner_id UUID REFERENCES users(id) ON DELETE CASCADE, creation_time TIMESTAMP, status STRING, current_location STRING, ext jsonb, CONSTRAINT "primary" PRIMARY KEY (city ASC, id ASC), INDEX vehicles_auto_index_fk_city_ref_users (city ASC, owner_id ASC), INVERTED INDEX ix_vehicle_ext (ext), FAMILY "primary" (id, city, type, owner_id, creation_time, status, current_location, ext) ); CREATE TABLE -- 3. 查看创建的 vehicles 表。 SHOW CREATE TABLE vehicles; table_name|create_statement ----------+---------------- vehicles |CREATE TABLE vehicles ( id UUID NOT NULL DEFAULT gen_random_UUID(), city STRING NOT NULL, type STRING NULL, owner_id UUID NULL, creation_time TIMESTAMP NULL, status STRING NULL, current_location STRING NULL, ext jsonb NULL, CONSTRAINT "primary" PRIMARY KEY (city ASC, id ASC), CONSTRAINT fk_owner_id_ref_users FOREIGN KEY (owner_id) REFERENCES users(id) ON DELETE CASCADE, INDEX vehicles_auto_index_fk_city_ref_users (city ASC, owner_id ASC), INVERTED INDEX ix_vehicle_ext (ext), INDEX vehicles_auto_index_fk_owner_id_ref_users (owner_id ASC), FAMILY "primary" (id, city, type, owner_id, creation_time, status, current_location, ext) ) (1 row) -- 4. 向 users 表中写入数据。 INSERT INTO users (name, dl) VALUES ('Annika', 'ABC-123'); INSERT 1 -- 5. 查看 users 表的内容。 SELECT * FROM users; id |city|name |address|credit_card|dl ------------------------------------+----+------+-------+-----------+------- fc47d311-e9c8-4627-9342-cd23822bc903| |Annika| | |ABC-123 (1 row) -- 6. 向 vehicles 表中写入数据。 INSERT INTO vehicles (city, owner_id) VALUES ('seattle', 'fc47d311-e9c8-4627-9342-cd23822bc903'); INSERT 1 -- 7. 查看 vehicles 表的内容。 SELECT * FROM vehicles; id |city |type|owner_id |creation_time|status|current_location|ext ------------------------------------+-------+----+------------------------------------+-------------+------+----------------+--- 75f4d3fd-b444-4c89-bdce-449974a35fed|seattle| |fc47d311-e9c8-4627-9342-cd23822bc903| | | | (1 row) -- 8. 删除 users 表内 id 为 fc47d311-e9c8-4627-9342-cd23822bc903 的行。 DELETE FROM users WHERE id = 'fc47d311-e9c8-4627-9342-cd23822bc903'; DELETE 1 -- 9. 查看 vehicles 表的内容。 SELECT * FROM vehicles; id|city|type|owner_id|creation_time|status|current_location|ext --+----+----+--------+-------------+------+----------------+--- (0 row)- 外键列必须创建索引。如果在
创建具有检查约束的表。
以下示例中创建一个名为
users的表,其中第一列是主键,最后一列设置了唯一性约束和检查约束来限制字符串的长度。系统自动为主键列和具有唯一约束的列创建索引。-- 1. 创建 users 表。 CREATE TABLE users ( id UUID PRIMARY KEY, city STRING, name STRING, address STRING, credit_card STRING, dl STRING UNIQUE CHECK (LENGTH(dl) < 8) ); CREATE TABLE -- 2. 查看表的列。 SHOW COLUMNS FROM users; column_name | data_type | is_nullable | column_default | generation_expression | indices | is_hidden | is_tag --------------+-----------+-------------+-------------------+-----------------------+-------------------------+-----------+--------- id | UUID | false | gen_random_uuid() | | {primary,users_dl_key} | false | false city | STRING | true | NULL | | {} | false | false name | STRING | true | NULL | | {} | false | false address | STRING | true | NULL | | {} | false | false credit_card | STRING | true | NULL | | {} | false | false dl | STRING | true | NULL | | {users_dl_key} | false | false (6 rows) -- 3. 查看表的索引。 SHOW INDEX FROM users; table_name | index_name | non_unique | seq_in_index | column_name | direction | storing | implicit -------------+---------------+------------+--------------+-------------+-----------+---------+----------- users | primary | false | 1 | id | ASC | false | false users | users_dl_key | false | 1 | dl | ASC | false | false users | users_dl_key | false | 2 | id | ASC | false | true (3 rows)创建 KV 存储镜像的表。
KaiwuDB 是建立在事务性和强一致性键值存储上的分布式 SQL 数据库。KaiwuDB 无法直接访问键值存储。用户可以创建一个包含两列表,并将其中一列设置为主键。这样 KaiwuDB 就可以直接访问键值存储。
-- 1. 创建 kv 表。 CREATE TABLE kv (k INT PRIMARY KEY, v BYTES); CREATE TABLE -- 2. 向表中写入数据。当表没有设置索引或外键时,UPSERT、UPDATE、DELETE 语句会以最小的开销转换为键值操作。以下示例中的 UPSERT 语句会转换为单个键值的 Put 操作。 UPSERT INTO kv VALUES (1, b'hello'); UPSERT 1使用
SELECT语句创建表。KaiwuDB 支持使用
CREATE TABLE AS语句根据SELECT语句的结果创建新表。以下示例使用users表的查询结果创建一个名为users_ny的表。-- 1. 使用 WHERE 子句查看 users 表中 city 名字为 new york 的内容。 SELECT * FROM users WHERE city = 'new york'; id |city |name |address|credit_card ------------------------------------+--------+-----+-------+----------- cd0bc9f9-707b-436c-9204-606244f4c4dd|new york|Petee| | (1 row) -- 2. 根据 users 表的查询结果创建 users_ny 表。 CREATE TABLE users_ny AS SELECT * FROM users WHERE city = 'new york'; CREATE TABLE -- 3. 查看 users_ny 表的内容。 SELECT * FROM users_ny; id |city |name |address|credit_card ------------------------------------+--------+-----+-------+----------- cd0bc9f9-707b-436c-9204-606244f4c4dd|new york|Petee| | (1 row)使用计算列创建表。
以下示例创建一个名为
users表,其中表的full_name列根据first_name列和last_name列计算得出。-- 1. 创建 users 表。 CREATE TABLE users (id UUID PRIMARY KEY DEFAULT gen_random_UUID(), city STRING, first_name STRING, last_name STRING, full_name STRING AS (CONCAT(first_name, ' ', last_name)) STORED, address STRING, credit_card STRING, dl STRING UNIQUE CHECK (LENGTH(dl) < 8)); CREATE TABLE -- 2. 写入数据。 INSERT INTO users (first_name, last_name) VALUES ('Lola', 'McDog'), ('Carl', 'Kimball'), ('Ernie', 'Narayan'); INSERT 3 -- 3. 查看表的内容。 SELECT * FROM users; id |city|first_name|last_name|full_name |address|credit_card|dl ------------------------------------+----+----------+---------+-------------+-------+-----------+-- 6d6b50e6-1492-4e57-8a12-12617e55c6f5| |Ernie |Narayan |Ernie Narayan| | | c4803c2e-c2e2-49bf-b912-80072229d785| |Lola |McDog |Lola McDog | | | f363db85-dfd5-40b8-a68e-f12ca8a4b84f| |Carl |Kimball |Carl Kimball | | | (3 rows)创建关系表并为表及其数据列添加注释信息。
以下示例创建一个名为
student的关系表并为表及其数据列添加注释信息。CREATE TABLE student (student_id UUID PRIMARY KEY DEFAULT, city STRING COMMENT = 'city for students', first_name STRING, last_name STRING, full_name STRING, address STRING, credit_card STRING) COMMENT = 'table for students'; CREATE TABLE创建具有标记列的表。
CREATE TABLE employee(label_column STRING(4000) LABEL, id INT PRIMARY KEY, name string not null, salary decimal);
查看表
SHOW TABLES 语句用于查看目标数据库和目标模式下的表或视图。
所需权限
用户拥有目标表的任何权限。
语法格式
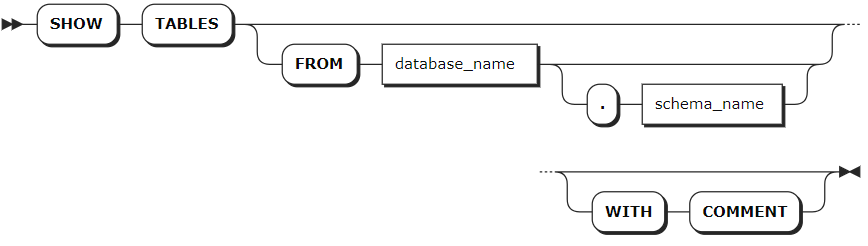
参数说明
| 参数 | 说明 |
|---|---|
database_name | 可选参数,表所在的数据库的名称。如未指定,则默认使用当前数据库。 |
schema_name | 可选参数,查看表的模式名称。如未指定,默认使用目标数据库查询路径中的第一个模式(public 模式)。 |
WITH COMMENT | 可选关键字,查看表的注释信息。 |
语法示例
查看当前数据库中的表。
show tables;执行成功后,控制台输出以下信息:
table_name|table_type ----------+---------- testblob |BASE TABLE users |BASE TABLE (2 rows)查看当前数据库中其他模式下的表。
以下示例查看当前数据库中
information_schema模式下的表。SHOW TABLES FROM information_schema;执行成功后,控制台输出以下信息:
table_name --------------------------------- administrable_role_authorizations applicable_roles check_constraints column_privileges columns CONSTRAINT_column_usage enabled_roles key_column_usage parameters ... (21 rows)查看其他数据库中的表。
以下示例查看
system数据库中public模式下的表。SHOW TABLES FROM system.public;执行成功后,控制台输出以下信息:
table_name ------------------------------- audits bo_white_list comments descriptor jobs kwdb_attribute kwdb_instance kwdb_k_schema_option kwdb_node_choice_info kwdb_node_info ... (52 rows)查看带有注释信息的表。
以下示例查看带有注释信息的表。
-- 1. 为 users 表添加注释。 COMMENT ON TABLE users IS 'This table contains information about users.'; COMMENT ON TABLE -- 2. 查看表的注释信息。 SHOW TABLES WITH COMMENT; table_name | table_type | comment ----------------+------------+----------------------------------------------- customers | BASE TABLE | orders | BASE TABLE | packages | BASE TABLE | testblob | BASE TABLE | users | BASE TABLE | This table contains information about users. (5 rows)
查看表的建表语句
SHOW CREATE [TABLE] <table_name> 语句用于查看当前或指定数据库下指定表的建表语句。如未指定数据库,则默认为当前数据库。
所需权限
用户拥有目标表的任何权限。
语法格式

参数说明
| 参数 | 说明 |
|---|---|
database_name | 待查看表所在的数据库的名称。如未指定,则默认使用当前数据库。 |
table_name | 待查看表的名称。 |
语法示例
查看当前数据库中指定表的建表语句。
以下示例查看当前数据库中
accounts表的建表语句。SHOW CREATE TABLE accounts; table_name| create_statement ------------+---------------------------------------------------- accounts | CREATE TABLE accounts ( | id INT8 NOT NULL DEFAULT unique_rowid(), | name STRING NULL, | balance DECIMAL NULL, | enabled BOOL NULL, | CONSTRAINT "primary" PRIMARY KEY (id ASC), | FAMILY "primary" (id, name, balance, enabled) | ) (1 row)查看其它数据库中指定表的建表语句。
以下示例查看
r数据库中t6表的建表语句。SHOW CREATE TABLE r.t6; table_name | create_statement --------------+----------------------------------- r.public.t6 | CREATE TABLE t6 ( | c1 NCHAR NULL, | FAMILY "primary" (c1, rowid) | ) (1 row)
修改表
ALTER TABLE 语句用于以下表操作:
- 在表中添加、修改、重命名或删除列。
- 在表中添加、验证、重命名或删除约束。
- 修改表的主键列。
- 修改表的区域配置。
- 创建表分区。
- 重命名现有表。表的重命名支持跨数据库迁移操作,即重命名后的表可迁移到新的数据库和新的模式中。避免在时序数据库下重命名关系表。
- 在表的特定行或范围上创建或移除拆分点,以提升性能。
- 重新分布表中的数据。
- 向表注入统计信息。
所需权限
- 在现有表中添加、修改、重命名或删除列
- 非三权分立模式下,用户是
admin角色的成员或者拥有目标表的 CREATE 权限。默认情况下,root用户属于admin角色。 - 三权分立模式下,用户是
sysadmin角色的成员或者是拥有目标表 CREATE 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。
- 非三权分立模式下,用户是
- 在现有表中添加、验证、重命名或删除约束
- 非三权分立模式下,用户是
admin角色的成员或者拥有目标表的 CREATE 权限。默认情况下,root用户属于admin角色。 - 三权分立模式下,用户是
sysadmin角色的成员或者是拥有目标表 CREATE 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。
- 非三权分立模式下,用户是
- 修改现有表上的主键列
- 非三权分立模式下,用户是
admin角色的成员或者拥有目标表的 CREATE 权限。默认情况下,root用户属于admin角色。 - 三权分立模式下,用户是
sysadmin角色的成员或者是拥有目标表 CREATE 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。
- 非三权分立模式下,用户是
- 修改表的区域配置
- 非三权分立模式下,用户是
admin角色的成员或者拥有目标表的 CREATE 权限或 ZONECONFIG 权限。默认情况下,root用户属于admin角色。 - 三权分立模式下,用户是
sysadmin角色的成员或者是拥有目标表 CREATE 权限或 ZONECONFIG 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。
- 非三权分立模式下,用户是
- 创建表分区
- 非三权分立模式下,用户是
admin角色的成员或者拥有目标表的 CREATE 权限。默认情况下,root用户属于admin角色。 - 三权分立模式下,用户是
sysadmin角色的成员或者是拥有目标表 CREATE 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。
- 非三权分立模式下,用户是
- 重命名表
- 重命名当前数据库中的表
- 非三权分立模式下,用户是
admin角色的成员或者拥有所属数据库的 CREATE 权限和原表的 DROP 权限。默认情况下,root用户属于admin角色。当表存在视图依赖时,系统不支持重命名表。 - 三权分立模式下,用户是
sysadmin角色的成员或者是拥有所属数据库的 CREATE 权限和原表的 DROP 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。当表存在视图依赖时,系统不支持重命名表。
- 非三权分立模式下,用户是
- 重命名表并将其迁移表到其他模式下
- 非三权分立模式下,用户是
admin角色的成员或者拥有目标数据库的 CREATE 权限和原表的 DROP 权限。默认情况下,root用户属于admin角色。 - 三权分立模式下,用户是
sysadmin角色的成员或者是拥有目标数据库的 CREATE 权限和原表的 DROP 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。
- 非三权分立模式下,用户是
- 重命名表并将其迁移表到其他数据库
- 非三权分立模式下,用户是
admin角色的成员或者拥有目标数据库的 CREATE 权限和原表的 DROP 权限。默认情况下,root用户属于admin角色。 - 三权分立模式下,用户是
sysadmin角色的成员或者是拥有目标数据库的 CREATE 权限和原表的 DROP 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。
- 非三权分立模式下,用户是
- 重命名当前数据库中的表
- 在表的特定行或范围上创建或移除拆分点
- 非三权分立模式下,用户是
admin角色的成员或者拥有目标表的 INSERT 权限。默认情况下,root用户属于admin角色。 - 三权分立模式下,用户是
sysadmin角色的成员或者是拥有目标表 INSERT 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。
- 非三权分立模式下,用户是
语法格式

支持的操作
- ADD
ADD COLUMN: 添加列,需指定列名和数据类型。COLUMN为可选关键字,如未使用,默认添加列。IF NOT EXISTS关键字可选。当使用IF NOT EXISTS关键字时,如果列名不存在,系统创建列。如果列名存在,系统创建列失败,但不会报错。当未使用IF NOT EXISTS关键字时,如果列名不存在,系统创建列。如果列名存在,系统报错,提示列名已存在。ADD CONSTRAINT:添加约束。更多详细信息,参见添加约束。
- ALTER
ALTER COLUMN: 修改列的默认值、是否非空以及列数据类型。ALTER PRIMARY KEY:修改表主键。
CONFIGURE ZONE:修改表的区域配置。更多详细信息,参见区域配置。- DROP
DROP COLUMN: 删除列,需指定列名。COLUMN为可选关键字,如未使用,默认删除列。IF EXISTS关键字可选。当使用IF EXISTS关键字时,如果列名存在,系统删除列。如果列名不存在,系统删除列失败,但不会报错。当未使用IF EXISTS关键字时,如果列名存在,系统删除列。如果列名不存在,系统报错,提示列名不存在。DROP CONSTRAINT:删除约束。更多详细信息,参见删除约束。
- PARTITION BY: 创建表的数据分区,更多详细信息,参见分区。
- RENAME
VALIDATE CONSTRAINT:检查列的值是否与列的约束匹配。SPLIT AT:在表的特定行或范围上创建拆分点,便于在数据分布不均匀、存在热点(hotspots)等情况下优化表的性能。WITH EXPIRATION子句用于设置拆分点的过期时间,便于系统在指定时间后自动移除拆分点。UNSPLIT AT:移除表的特定行或范围上的拆分点。SELECT子句可用于指定要移除拆分点的位置。UNSPLIT ALL:移除表中所有已被拆分的范围的拆分点,便于在数据分布不均匀、存在热点(hotspots)等情况下优化表的性能。SCATTER:重新分布表中的数据,以实现更好的负载均衡。FROM 子句可用于指定要重新分布的数据范围。INJECT STATISTICS:实验性功能,用于向表注入统计信息,可用于测试和调试,在生产环境中应谨慎使用。
参数说明
| 参数 | 说明 |
|---|---|
table_name | 表名,支持通过 <database_name>.<table_name> 指定其他数据库中的表。如未指定,则默认使用当前数据库。 |
column_name | 列名,新增列名不得与待修改表的当前列名重复。 |
typename | 列的数据类型。支持添加标记列用以实现行级强制访问控制,类型为 STRING(4000)。添加标记列之后,原有数据行的标记列数据为 NULL。 |
col_qual_list | 列定义列表,支持定义以下信息: - <col_qualification_elem>:NULL、NOT NULL、UNIQUE、PRIMARY KEY、CHECK、DEFAULT、REFERENCES、AS、LABEL。- CONSTRAINT <constraint_name> <col_qualification_elem> - COLLATE <collation_name> - FAMILY <family_name>:如果未指定列族,则该列将被添加到第一个列族。 - CREATE FAMILY [<family_name>] 说明 KaiwuDB 不支持直接添加带有外键约束的列。有关为列添加外键约束的详细信息,参见添加约束。 |
constraint_name | 约束名。该名称在表中必须唯一,并且遵循数据库标识符规则。 |
constraint_elem | 待添加的约束,支持以下约束: - CHECK:列值满足指定的条件或表达式。- UNIQUE:列值都唯一,NULL 值除外。- FOREIGN KEY:在为列添加外键约束前,该列必须已创建索引。如未创建,先使用 CREATE INDEX 语句创建索引,然后再添加外键约束。更多详细信息,参见添加约束。 |
a_expr | 待使用的默认值。 |
collation_name | 排序规则的名称。 |
index_params | 索引信息。更多详细信息,参见索引。 |
interleave_clause | 可选项,支持使用交错索引(Interleaving Indexes)优化查询性能, 格式为 INTERLEAVE IN PARENT <table_name> (<name_list>)。这会改变 KaiwuDB 存储数据的方式。 |
json_data | 向目标表写入的统计信息,格式必须是JSON格式,并使用单引号包围。 |
语法示例
重命名表
以下示例将
users表重命名为re_users。-- 1. 查看当前数据库中的表。 SHOW TABLES; table_name ---------- kv users (2 rows) -- 2. 将 users 表重命名为 re_users。 ALTER TABLE users RENAME TO re_users; ALTER TABLE -- 3. 查看当前数据库中的表。 SHOW TABLES; table_name ---------- kv re_users (2 rows)创建拆分点
以下示例根据
vehicleid的数值为vehicles表创建了拆分点。-- 1. 查看表数据。 SELECT * FROM vehicles; vehicleid | licenseplate | owner | model | year ------------+--------------+-------+-------+------- 1 | 京A11111 | 李明 | 奔驰 | 2020 2 | 京A22222 | 赵志 | 别克 | 2022 (2 rows) -- 2. 设置拆分点 ALTER TABLE vehicles SPLIT AT SELECT vehicleid from vehicles where vehicleid = 1; key | pretty | split_enforced_until -----------+---------------+----------------------------------- \xda8989 | /Table/82/1/1 | 2262-04-11 23:47:16.854776+00:00 (1 row)移除所有拆分点
以下示例移除了
vehicles表上的所有拆分点。ALTER TABLE vehicles UNSPLIT ALL;重新分布数据
以下示例对
vehicles表上的数据进行了重新分布。ALTER TABLE vehicles SCATTER; key | pretty -------+------------ \xda | /Table/82 (1 row)向表内注入统计信息
以下示例将 JSON 格式的统计数据写入
kv表中。ALTER TABLE kv INJECT STATISTICS '[{"name":"__auto__","created_at":"2000-01-01 00:00:00+00:00","columns":["k"],"row_count":2223475796173842391,"distinct_count":405727959889499775,"null_count":1571059772371006376},{"name":"__auto__","created_at":"2000-01-01 00:00:00+00:00","columns":["v"],"row_count":2223475796173842391,"distinct_count":2209895385460769436,"null_count":131122807856894709}]';向表中添加标记列
ALTER TABLE devices ADD COLUMN label_column STRING(4000) LABEL;
删除表
DROP TABLE 语句用于从数据库中删除表及其所有索引和关联的触发器。
说明
目标表已开启复制,或目标表所在的数据库已开启复制且该表为库内唯一一张表,则不支持删除,需先停止相关复制任务,再执行删除表操作。
所需权限
- 非三权分立模式下,
- 用户是
admin角色的成员或者拥有目标表的 DROP 权限。默认情况下,root用户属于admin角色。 - 当目标表存在关联的外键约束或与其他交错表关联,用户还需要拥有关联表的 REFERENCES 权限。
- 当目标表存在视图等依赖关系,用户还需要拥有目标表的 DROP 权限和所有依赖此表视图的 DROP 权限。
- 用户是
- 三权分立模式下,
- 用户是
sysadmin角色的成员或者是拥有目标表 DROP 权限的普通用户。默认情况下,sysroot用户属于sysadmin角色。 - 当目标表存在关联的外键约束或与其他交错表关联,普通用户还需要拥有关联表的 REFERENCES 权限。
- 当目标表存在视图等依赖关系,普通用户还需要拥有目标表的 DROP 权限和所有依赖此表视图的 DROP 权限。
- 用户是
语法格式

参数说明
| 参数 | 说明 |
|---|---|
IF EXISTS | 可选关键字。当使用 IF EXISTS 关键字时,如果目标表存在,系统删除目标表。如果目标表不存在,系统删除目标表失败,但不会报错。当未使用 IF EXISTS 关键字时,如果目标表存在,系统删除目标表。如果目标表不存在,系统报错,提示目标列不存在。 |
table_name_list | 要删除的表名列表。支持一次删除一个或多个表,表名之间使用逗号(,)隔开。 |
CASCADE | 可选关键字。删除目标表及其关联对象。CASCADE 不会列出待删除的关联对象,应谨慎使用。 |
RESTRICT | 默认设置,可选关键字。如果其他对象依赖目标表,则无法删除该表。 |
语法示例
以下示例删除当前数据库中的 kv 表。
-- 1. 查看当前数据库中的表。
SHOW TABLES;
table_name
----------
kv
re_users
(2 rows)
-- 2. 删除 kv 表。
DROP TABLE kv;
DROP TABLE
-- 3. 查看当前数据库中的表。
SHOW TABLES;
table_name
----------
re_users
(1 row)